 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Alzheimer's Disease Detection from Retinal OCT Images: A UK Biobank Study
Nov 07, 2025Alterations in retinal layer thickness, measurable using Optical Coherence Tomography (OCT), have been associated with neurodegenerative diseases such as Alzheimer's disease (AD). While previous studies have mainly focused on segmented layer thickness measurements, this study explored the direct classification of OCT B-scan images for the early detection of AD. To our knowledge, this is the first application of deep learning to raw OCT B-scans for AD prediction in the literature. Unlike conventional medical image classification tasks, early detection is more challenging than diagnosis because imaging precedes clinical diagnosis by several years. We fine-tuned and evaluated multiple pretrained models, including ImageNet-based networks and the OCT-specific RETFound transformer, using subject-level cross-validation datasets matched for age, sex, and imaging instances from the UK Biobank cohort. To reduce overfitting in this small, high-dimensional dataset, both standard and OCT-specific augmentation techniques were applied, along with a year-weighted loss function that prioritized cases diagnosed within four years of imaging. ResNet-34 produced the most stable results, achieving an AUC of 0.62 in the 4-year cohort. Although below the threshold for clinical application, our explainability analyses confirmed localized structural differences in the central macular subfield between the AD and control groups. These findings provide a baseline for OCT-based AD prediction, highlight the challenges of detecting subtle retinal biomarkers years before AD diagnosis, and point to the need for larger datasets and multimodal approaches.
A Survey on Automated Diagnosis of Alzheimer's Disease Using Optical Coherence Tomography and Angiography
Sep 07, 2022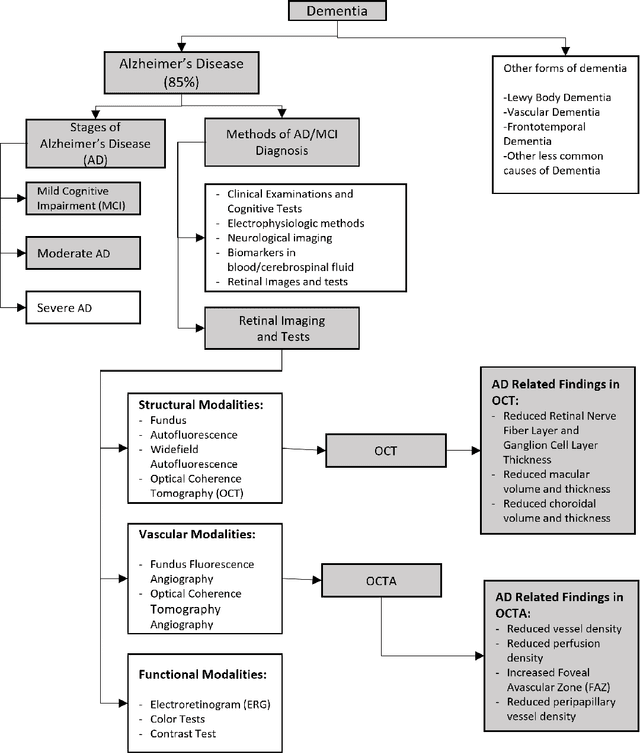
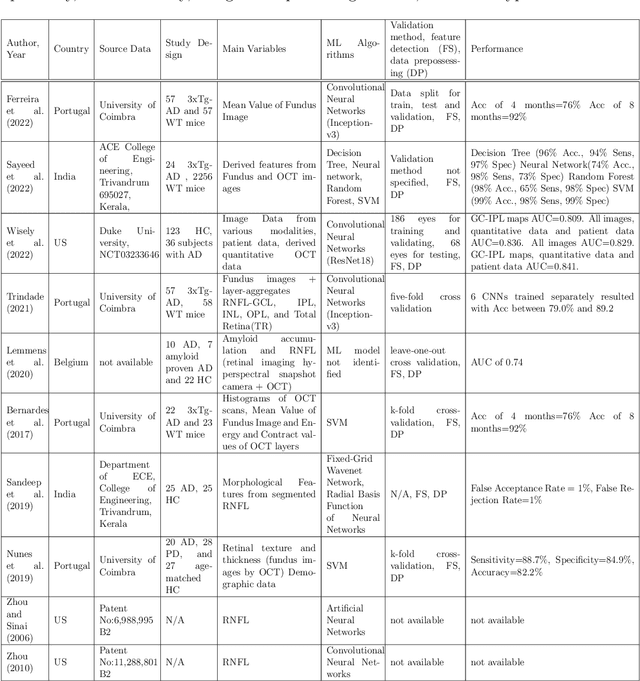
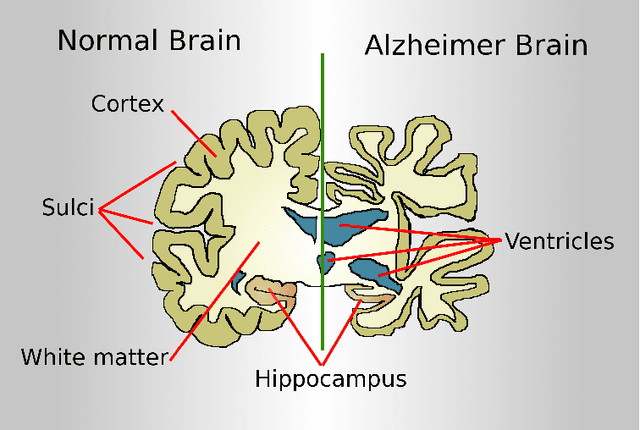
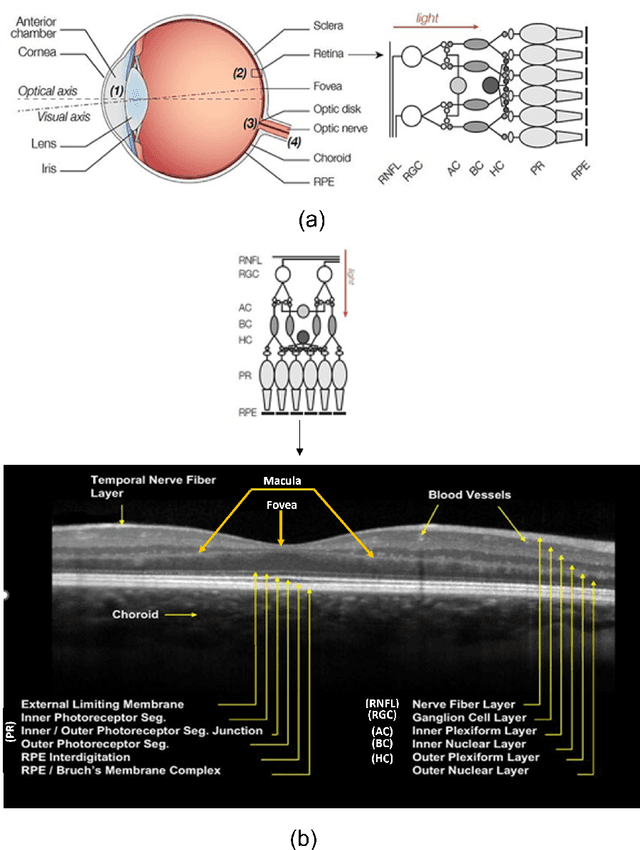
Retinal optical coherence tomography (OCT) and optical coherence tomography angiography (OCTA) are promising tools for the (early) diagnosis of Alzheimer's disease (AD). These non-invasive imaging techniques are cost-effective and more accessible than alternative neuroimaging tools. However, interpreting and classifying multi-slice scans produced by OCT devices is time-consuming and challenging even for trained practitioners. There are surveys on machine learning and deep learning approaches concerning the automated analysis of OCT scans for various diseases such as glaucoma. However, the current literature lacks an extensive survey on the diagnosis of Alzheimer's disease or cognitive impairment using OCT or OCTA. This has motivated us to do a comprehensive survey aimed at machine/deep learning scientists or practitioners who require an introduction to the problem. The paper contains 1) an introduction to the medical background of Alzheimer's Disease and Cognitive Impairment and their diagnosis using OCT and OCTA imaging modalities, 2) a review of various technical proposals for the problem and the sub-problems from an automated analysis perspective, 3) a systematic review of the recent deep learning studies and available OCT/OCTA datasets directly aimed at the diagnosis of Alzheimer's Disease and Cognitive Impairment. For the latter, we used Publish or Perish Software to search for the relevant studies from various sources such as Scopus, PubMed, and Web of Science. We followed the PRISMA approach to screen an initial pool of 3073 references and determined ten relevant studies (N=10, out of 3073) that directly targeted AD diagnosis. We identified the lack of open OCT/OCTA datasets (about Alzheimer's disease) as the main issue that is impeding the progress in the field.
Adaptive Convolution Kernel for Artificial Neural Networks
Sep 14, 2020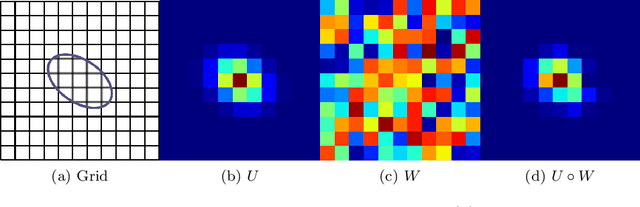
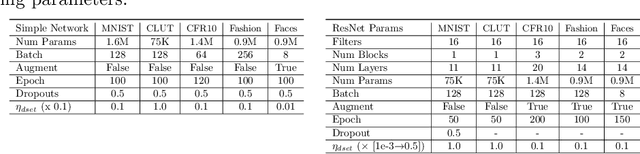

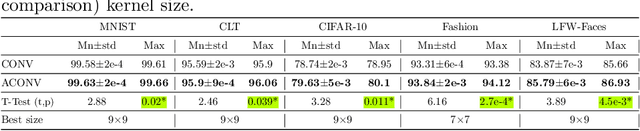
Many deep neural networks are built by using stacked convolutional layers of fixed and single size (often 3$\times$3) kernels. This paper describes a method for training the size of convolutional kernels to provide varying size kernels in a single layer. The method utilizes a differentiable, and therefore backpropagation-trainable Gaussian envelope which can grow or shrink in a base grid. Our experiments compared the proposed adaptive layers to ordinary convolution layers in a simple two-layer network, a deeper residual network, and a U-Net architecture. The results in the popular image classification datasets such as MNIST, MNIST-CLUTTERED, CIFAR-10, Fashion, and ``Faces in the Wild'' showed that the adaptive kernels can provide statistically significant improvements on ordinary convolution kernels. A segmentation experiment in the Oxford-Pets dataset demonstrated that replacing a single ordinary convolution layer in a U-shaped network with a single 7$\times$7 adaptive layer can improve its learning performance and ability to generalize.
An Adaptive Locally Connected Neuron Model: Focusing Neuron
Aug 31, 2018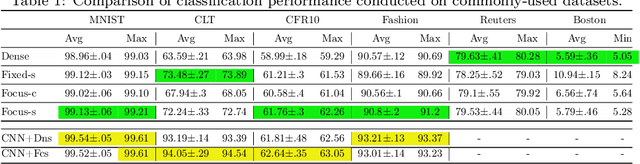
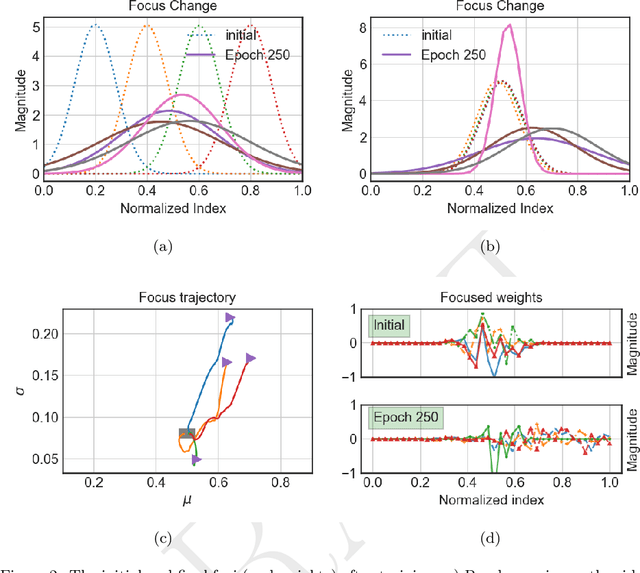
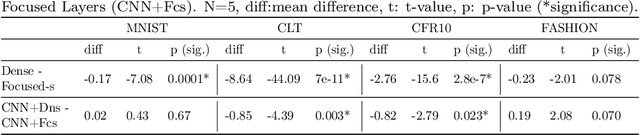
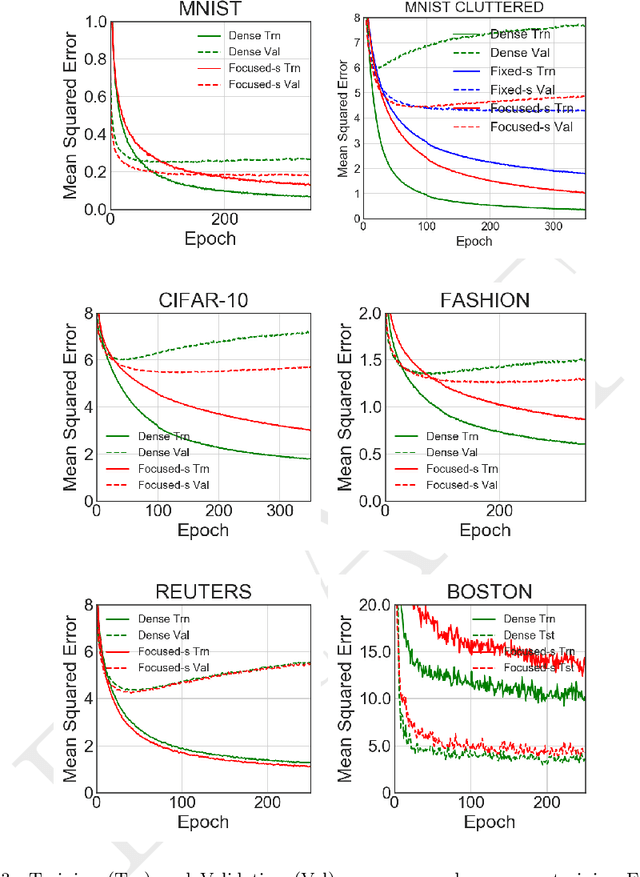
We present a new artificial neuron model capable of learning its receptive field in the spatial domain of inputs. The name for the new model is focusing neuron because it can adapt both its receptive field location and size (aperture) during training. A network or a layer formed of such neurons can learn and generate unique connection structures for particular inputs/problems. The new model requires neither heuristics nor additional optimizations. Hence, all parameters, including those controlling the focus could be trained using the stochastic gradient descent optimization. We have empirically shown the capacity and viability of the new model with tests on synthetic and real datasets. We have constructed simple networks with one or two hidden layers; also employed fully connected networks with the same configurations as controls. In noise-added synthetic Gaussian blob datasets, we observed that focusing neurons can steer their receptive fields away from the redundant inputs and focused into more informative ones. Tests on common datasets such as MNIST have shown that a network of two hidden focusing layers can perform better (99.21% test accuracy) than a fully connected dense network with the same configuration.
Learning Filter Scale and Orientation In CNNs
Feb 13, 2018



Convolutional neural networks have many hyperparameters such as the filter size, number of filters, and pooling size, which require manual tuning. Though deep stacked structures are able to create multi-scale and hierarchical representations, manually fixed filter sizes limit the scale of representations that can be learned in a single convolutional layer. This paper introduces a new adaptive filter model that allows variable scale and orientation. The scale and orientation parameters of filters can be learned using back propagation. Therefore, in a single convolution layer, we can create filters of different scale and orientation that can adapt to small or large features and objects. The proposed model uses a relatively large base size (grid) for filters. In the grid, a differentiable function acts as an envelope for the filters. The envelope function guides effective filter scale and shape/orientation by masking the filter weights before the convolution. Therefore, only the weights in the envelope are updated during training. In this work, we employed a multivariate (2D) Gaussian as the envelope function and showed that it can grow, shrink, or rotate by updating its covariance matrix during back propagation training . We tested the new filter model on MNIST, MNIST-cluttered, and CIFAR-10 and compared the results with the networks that used conventional convolution layers. The results demonstrate that the new model can effectively learn and produce filters of different scales and orientations in a single layer. Moreover, the experiments show that the adaptive convolution layers perform equally; or better, especially when data includes objects of varying scale and noisy backgrounds.
Adaptive Gray World-Based Color Normalization of Thin Blood Film Images
Jul 14, 2016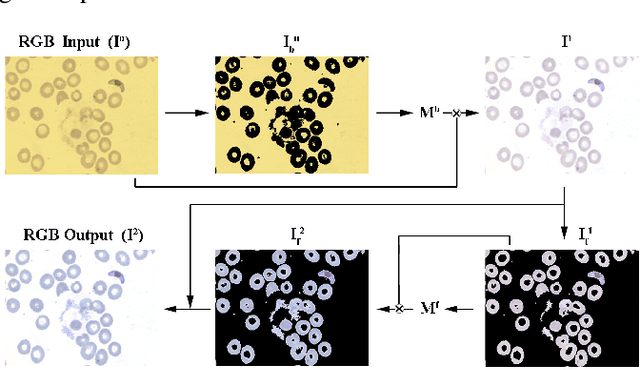
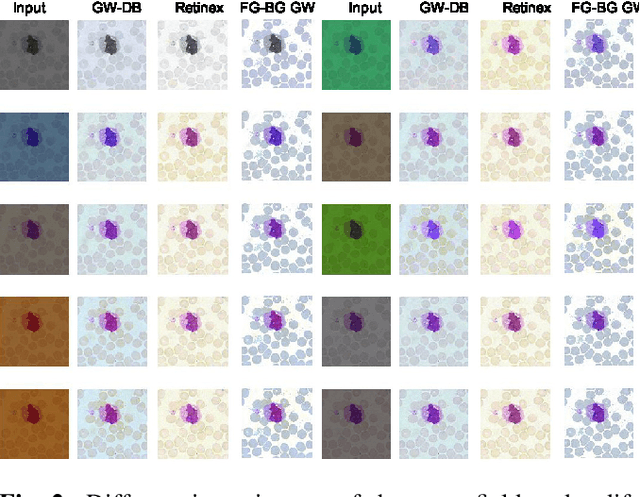
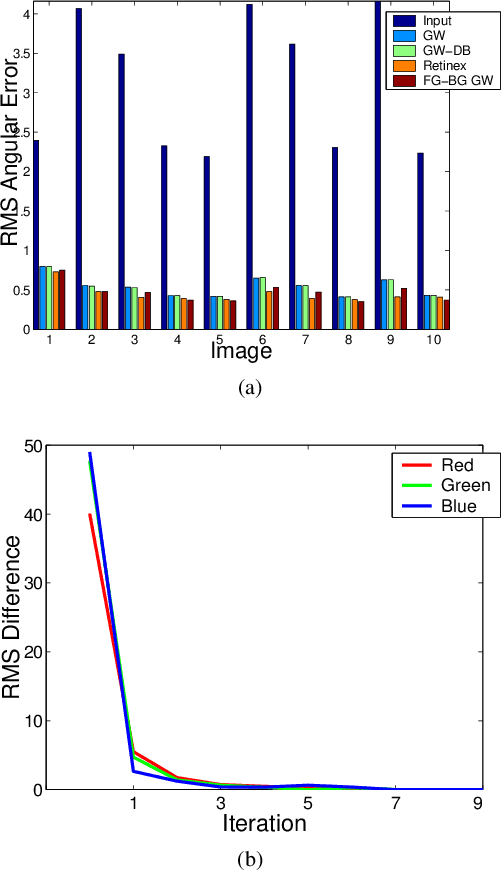
This paper presents an effective color normalization method for thin blood film images of peripheral blood specimens. Thin blood film images can easily be separated to foreground (cell) and background (plasma) parts. The color of the plasma region is used to estimate and reduce the differences arising from different illumination conditions. A second stage normalization based on the database-gray world algorithm transforms the color of the foreground objects to match a reference color character. The quantitative experiments demonstrate the effectiveness of the method and its advantages against two other general purpose color correction methods: simple gray world and Retinex.
Assessment of algorithms for mitosis detection in breast cancer histopathology images
Nov 21, 2014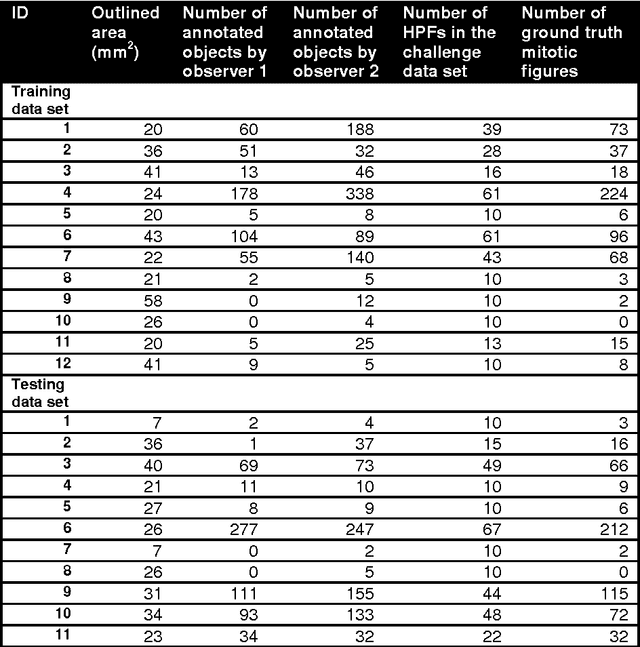

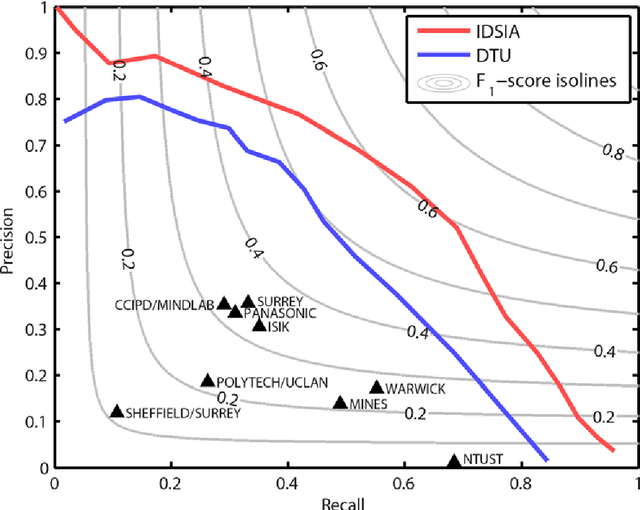
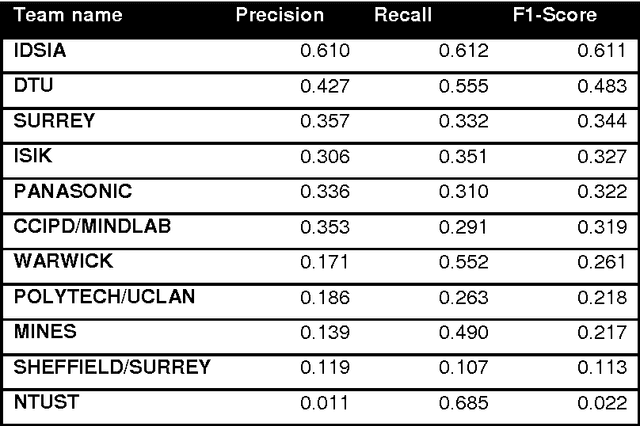
The proliferative activity of breast tumors, which is routinely estimated by counting of mitotic figures in hematoxylin and eosin stained histology sections, is considered to be one of the most important prognostic markers. However, mitosis counting is laborious, subjective and may suffer from low inter-observer agreement. With the wider acceptance of whole slide images in pathology labs, automatic image analysis has been proposed as a potential solution for these issues. In this paper, the results from the Assessment of Mitosis Detection Algorithms 2013 (AMIDA13) challenge are described. The challenge was based on a data set consisting of 12 training and 11 testing subjects, with more than one thousand annotated mitotic figures by multiple observers. Short descriptions and results from the evaluation of eleven methods are presented. The top performing method has an error rate that is comparable to the inter-observer agreement among pathologists.